Wenhui Tan, Boyuan Li, Chuhao Jin, Wenbing Huang, Xiting Wang, Ruihua Song
Project Page | Arxiv
Abstract
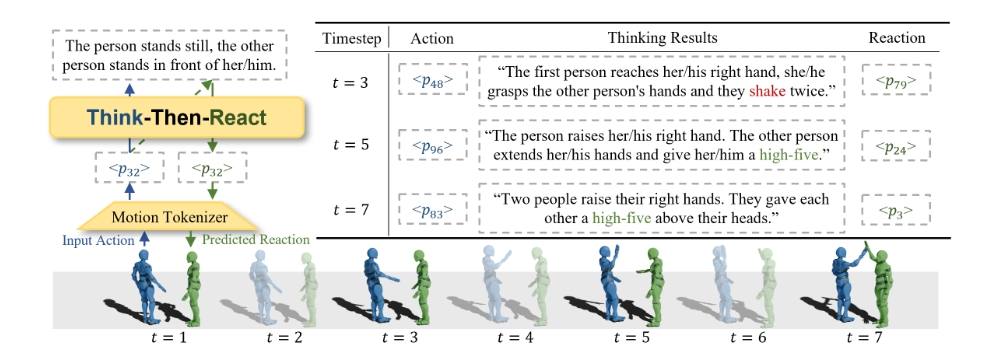
Modeling human-like action-to-reaction generation has significant real-world applications, like human-robot interaction and games. Despite recent advancements in single-person motion generation, it is still challenging to well handle action-to-reaction generation, due to the difficulty of directly predicting reaction from action sequence without prompts, and the absence of a unified representation that effectively encodes multi-person motion. To address these challenges, we introduce Think-Then-React (TTR), a large language model-based framework designed to generate human-like reactions. First, with our fine-grained multimodal training strategy, TTR is capable to unify two processes during inference: a thinking process that explicitly infers action intentions and reasons corresponding reaction description, which serve as semantic prompts, and a reacting process that predicts reactions based on input action and the inferred semantic prompts. Second, to effectively represent multi-person motion in language models, we propose a unified motion tokenizer by decoupling egocentric pose and absolute space features, which effectively represents action and reaction motion with same encoding. Extensive experiments demonstrate that TTR outperforms existing baselines, achieving significant improvements in evaluation metrics, such as reducing FID from 3.988 to 1.942.